3-х уровневый конвейер STM8: перевод глав 3, 4, 5 руководства по программированию микроконтроллеров STM8 (PM0044)
разделы: STM8 , АССЕМБЛЕР , дата: 4 марта 2018г.

Вначале я хотел посвятить архитектуре STM8 краткую вводную главу, но когда начал вчитываться в документацию, то понял, что переводить надо все. Потому что лучше, чем написано в документации, я не скажу. Посвятить целую статью теории - это несколько выходит за формат моего сайта. Но все, что там изложено, стоит того, чтобы это прочесть.
Наибольшие вопросы в STM8 у меня вызывал 3-уровневый конвейер, поэтому в основу перевода легла глава, рассмативающая работу этого конвейера.
Если сравнивать систему команд STM8 с ассемблером AVR, то здесь имеется большое количество 16-битных команд, целочисленное умножение и деление, условные переходы объединены с проверками, не надо вечно перепрыгивать через команду. Имеются полноценные битовые команды, которые выполняются за один цикл. В целом, мне показалась, что писать на ассемблере STM8 можно также легко как на Си.
-
Содержание::
- Описание ядра STM8
- Интерфейс памяти STM8
-
Принципы работы конвейера
- Описание уровней конвейера
- Этап выборки (fetch)
- Декодирование и вычисление адреса
- Этап исполнения
- Конфликты на шине данных
- Примеры работы конвейера
- Предварительное соглашение
- Пример оптимизированной работы конвейера - выполнение программы из флеш-памяти
- Пример оптимизированной работы конвейера - выполнение программы из ОЗУ
- Пример работы конвейера с инструкциями перехода JP и CALL
- Приостановка конвейера
- Работа конвейера с ожиданием в один цикл
3 Описание ядра STM8
3.1 Введение
ЦПУ имеет полностью 8-битную архитектуру с 16-битными операциями на индексных регистрах (для вычисления адресов). Шесть внутренних регистров позволяют эффективно оперировать с 8-битными данными. Система команд состоит из 80 базовых инструкций ЦПУ. 20 режимов адресации позволяют адресовать к 6 внутренним регистрам и 16 Мбайтам оперативной памяти и/или регистрам ввода-вывода.
3.2 Регистры ЦПУ
Шесть регистров ЦПУ показаны на рисунке 1. Перед входом в обработчик прерывания содержимое этих регистров сохраняется в стеке в порядке, показанном на рисунке 2. При возвращении из обработчика прерывания содержимое регистров восстанавливается.
Аккумулятор
Аккумулятор - это главный 8-битный регистр, используемый для хранения операнда и результата арифметических и логических операций, а также для операций с данными.
Индексные регистры (X и Y)
Это 16-битные регистры, используемые для вычисления адреса или для хранения временных значений при операциях с данными. В большинстве случаев компилятор генерирует прекод инструкции (PRE) для обозначения того, что следующая инструкция ссылается на Y регистр. Оба регистра X и Y автоматически сохраняются при возникновения прерывания.
Программный счетчик (PC)
Программный счетчик - это 24-битный регистр для хранения адреса следующей инструкции. Он автоматически обновляется после выполнения каждой инструкции ЦПУ. Таким образом STM8 может адресовать 16-Мбайтное адресное пространство.
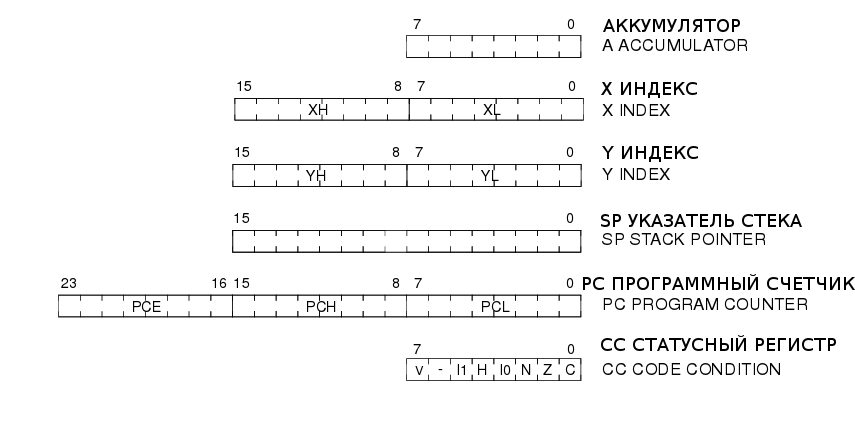
рисунок 1. Регистры ЦПУ
Указатель стека (SP)
Указатель стека - это 16-разрядный регистр. Он содержит адрес следующей свободной ячейки стека. В зависимости от модели микроконтроллера, старшие биты указателя могут быть аппаратно предустановлены в то или иное значение.
Стек используется для сохранения содержимого регистров ЦПУ при вызове подпрограммы или возникновения прерывания. Пользователь также может напрямую использовать стек через инструкции POP и PUSH.
После подачи питания на микроконтроллер, указатель стека устанавливается в наибольшее допустимое значение. Значение регистра уменьшается при помещении данных в стек и увеличивается при извлечении их оттуда. Когда указатель достигнет нижней допустимой границы, его значение снова будет установлено в максимально допустимое значение. Тогда ранее сохраненные данные будет переписываться и, следовательно, они будут потеряны.
Вызов подпрограммы занимает две или три ячейки стека.
При возникновении прерывания регистры ЦПУ(CC, X, Y, A, PC) сохраняются в стеке. Эта операция занимает 9 тактов и использует 9 байт ОЗУ.
Примечание. Режимы WFI/HALT сохраняют содержимое регистров заранее. Т.о., при возникновении прерывания скорость реагирования на него увеличивается.
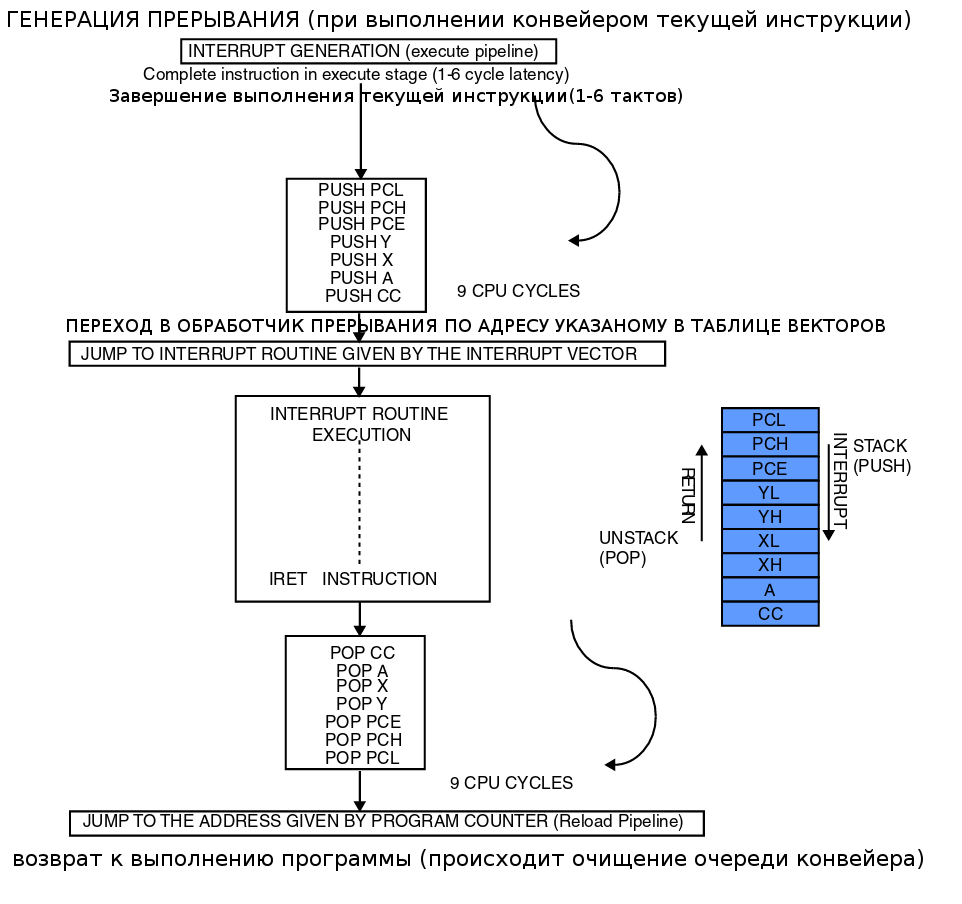
рисунок 2. Сохранение и восстановление содержимого регистров ЦПУ при возникновении прерывания
Глобальный конфигурационный регистр (CFG_GCR)
Глобальный конфигурационный регистр привязан к адресу в оперативной памяти. Он управляет конфигурацией процессора и включает в себя AL-бит:
AL - уровень активности(activation level)
Если AL сброшен в ноль, то инструкция IRET (выход из обработчика прерывания) восстановит содержимое регистров из стека, и основная программа продолжит выполнение со следующей инструкции после WFI.
Если AL установлен в единицу (когда работают только прерывания), то IRET вернет ЦПУ обратно в режим WFI/HALT, без извлечения содержимого регистров из стека.
Этот бит отвечает за пониженное энергопотребление микроконтроллером. В режиме пониженного энергопотребления микроконтроллер большую часть времени проводит в режимах WFI/HALT, изредка пробуждаясь (через прерывания) для выполнения своих задач. Эти задачи могут быть настолько короткими, что могут выполняться непосредственно в обработчике прерывания, без возвращения в основную программу. В таком случае флаг AL устанавливается в 1 переводом микроконтроллера в режим пониженного энергосбережения (с помощью инструкций WFI/HALT). В результате время выполнения обработчика прерывания уменьшается за счет того, что содержимое регистров ЦПУ не сохраняется и не восстанавливается каждый раз при возникновении прерывания.
Статусный регистр (CC)
Статусный регистр - это 8-битный регистр, в который заносятся флаги результата только что выполненной инструкции ЦПУ. Эти флаги могут быть проанализированы независимо друг от друга специальными инструкциями, в результате чего могут быть приняты те или иные действия.
● V: флаг переполнения (overflow)
Если V флаг установлен, то это показывает, что при выполнении последней знаковой арифметической операции старший бит - MSB - был установлен в единицу. Для подробностей смотрите описание инструкций: INC, INCW, DEC, DECW, NEG, NEGW, ADD, ADC, SUB, SUBW, SBC, CP, CPW.
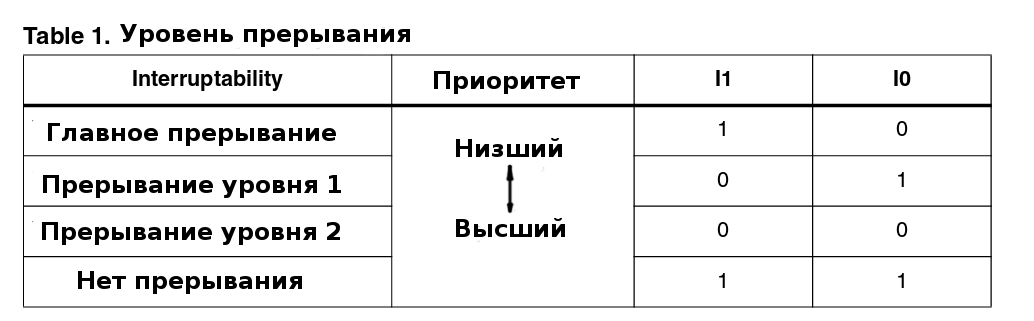
● I1: маска прерывания первого уровня
Этот флаг работает совместно с флагом I0 и определяет текущий уровень прерывания согласно нижеследующей таблице. Эти флаги могут быть установлены программно следующими инструкциями: RIM, SIM, HALT, WFI, IRET, TRAP и POP. Или они могут быть установлены автоматически аппаратным способом при входе в обработчик прерывания.
● H: флаг полупереноса
Этот флаг устанавливается в 1, когда произошел перенос из 3-го бита в 4-й при выполнении инструкций ADD или ADC. Флаг H используется при работе с BCD-арифметикой. В случае ADDW, SUBW этот флаг устанавливается, когда произошел перенос между 7-м и 8-м битами индексных 16-битных регистров.
● I0: маска прерывания нулевого уровня
см. флаг I1.
● N: флаг отрицательного числа
Флаг устанавливается в 1, когда последняя арифметическая, логическая или операция с данными привела к появлению отрицательного числа (т.е. старший бит был установлен в единицу).
● Z: флаг нуля
Флаг устанавливается в 1, когда последняя арифметическая, логическая или операция с данными привела к появлению нуля.
● C: флаг переноса
Флаг переноса - "C" устанавливается тогда, когда в результате последней арифметической операции в АЛУ со старшим битом (MSB) произошел перенос или заимствование. Этот бит также участвует в операциях проверки, ветвления, сдвига и загрузки. Смотрите описания инструкций: ADD, ADC, SUB, SBC для подробностей.
В операциях битового тестирования инструкции работают с копией флага "C". Смотрите описания инструкций: BTJF, BTJT для подробностей.
В операциях сдвига "C" флаг будет обновлен. Смотрите описания инструкций: RRC, RLC, SRL, SLL, SRA для подробностей.
Флаг может быть программно установлен, сброшен, или может изменить значение на противоположное с помощью инструкций: SCF, RCF, CCF.
Пример: сложение
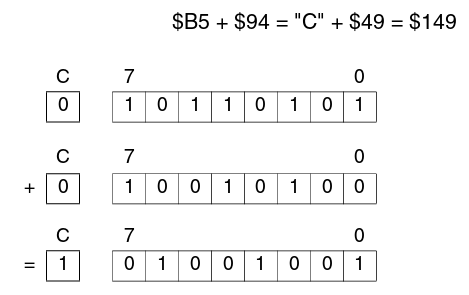
Влияние выполнения каждой инструкции на статусный регистр отображено в таблице инструкций STM8. Для примера:
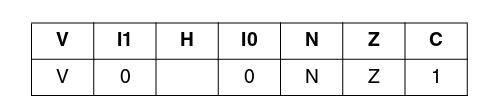
Где:
N - не влияет;
Имя флага - влияет;
1 - устанавливается в единицу;
0 - устанавливается в ноль.
4 Интерфейс памяти STM8
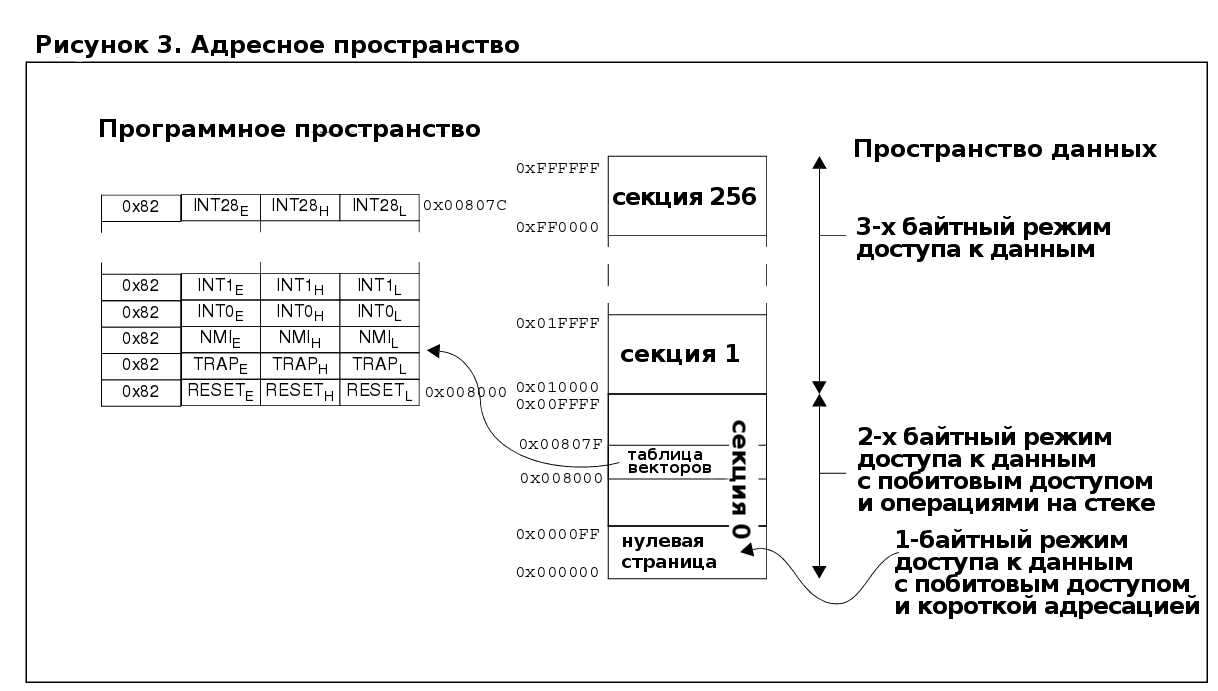
4.1 Программное пространство
Программное пространство равно 16 Мбайт и оно линейно. Отличия 1-, 2-, и 3-байтных режимов адресации показаны на рисунке 3.
● "Страница" [0xXXXX00 до 0xXXXXFF] - это 256-байтный участок памяти с одинаковыми двумя старшими байтами (ХХХХ определяют номер страницы).
● "Секция" [0xXX0000 to 0xXXFFFF] - это 64КБ участок памяти с одинаковым старшим байтом (ХХ определяют номер секции).
Reset и таблица векторов расположены по адресу 0х8000 для семейства STM8. (Примечание: для последующих серий адрес может быть изменен.) Таблица векторов имеет 32 4-байтных записей: RESET, Trap, NMI и 29 векторов нормальных пользовательских прерываний. Каждая запись содержит опкод 0x82 и следующее за ним 24-битное значение: PCE, PCH, PCL - адрес расположения обработчика прерывания. Главная программа и обработчики прерываний могут располагаться в любом месте 16МБ пространства.
Инструкции CALL/CALLR и RET должны использоваться только в пределах одной секции. CALL/RET использует смещение относительно текущего значения PCE регистра. Для JP адрес перехода должен быть длиной 16 или 17 (при индексной адресации) бит. Это значение добавляется к текущему значению PCE. Чтобы переместиться на любой адрес программного пространства, инструкции перехода JPF и CALLF используют расширенную адресацию с тремя байтами в качестве адреса. В то же время RETF возвращает из стека три байта адреса возврата.
Т.к. программное пространство линейно, секции могут пересекаться двумя способами: выполнением следующей инструкции (PC+1), относительным переходом, и, в некоторых случаях, инструкцией JP (с использованием индексной адресации).
Примечание: в целях безопасного использования памяти, функции, пересекающие границы секторов,
ОБЯЗАНЫ:
- вызываться инструкцией CALLF;
- включать в себя инструкции только с расширенной адресацией(CALLF и JPF)
Все метки относятся к нулевой секции (пример: JP [ptr.w], - где ptr.w расположен в нулевой секции, а JP адресуется к текущей секции).
Все неправильные опкоды, считанные из программного пространства, приводят микроконтроллер к перезагрузке.
4.2 Пространство данных
Размер пространства данных составляет 16 Мбайт. Т.к. стек расположен в нулевой секции, доступ к данным за пределами нулевой и первой секции осуществляется только инструкцией LDF. Для максимальной эффективности вашей программы часто используемые данные должны располагаться в нулевой секции.
Все метки данных расположены исключительно в нулевой секции.
Индексная адресация (16-битный индексный регистр в сочетании с длинным смещением) позволяет адресовать нулевую и первую секцию.
Вся периферия имеет собственные адреса в адресном пространстве.
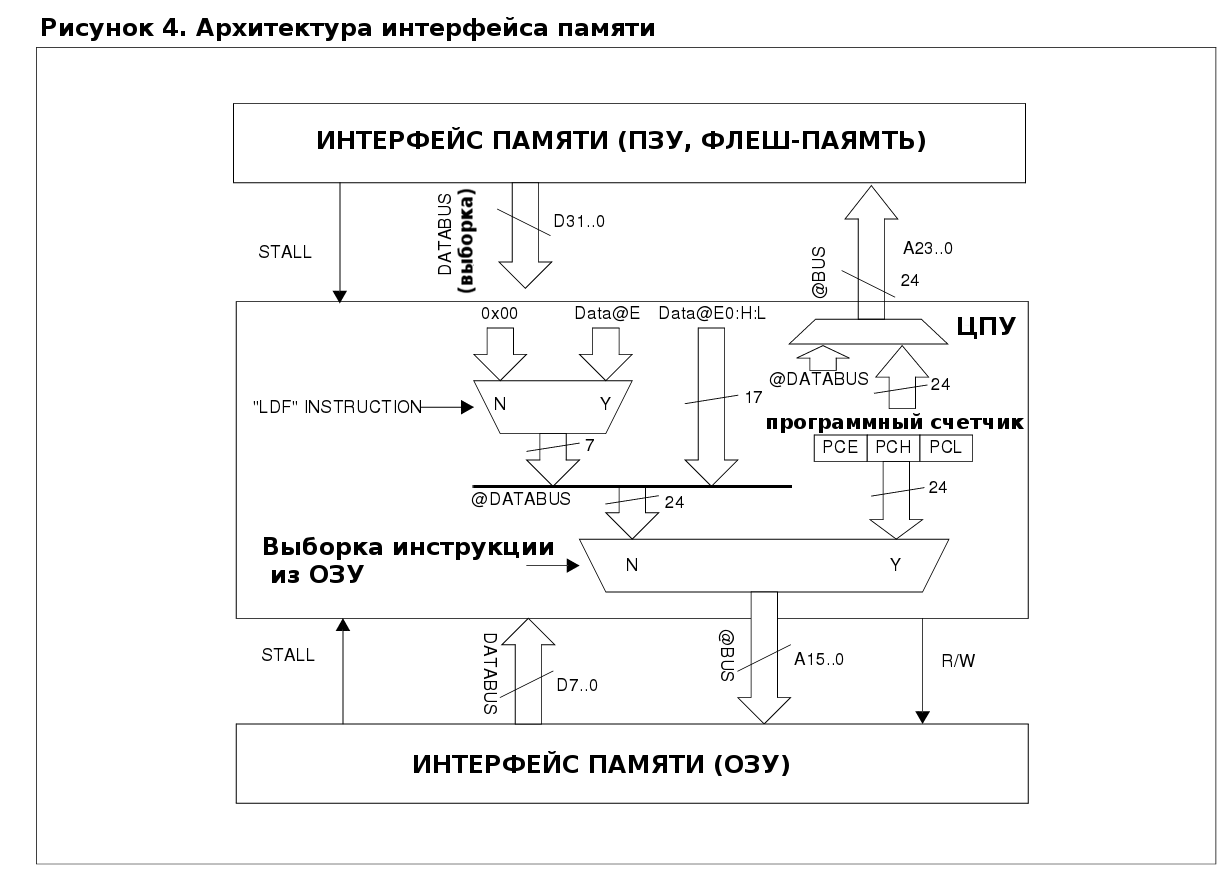
4.3 Архитектура интерфейса памяти
STM8 имеет гарвардскую архитектуру с независимыми шинами для программы и для данных. Однако, логически, адресное пространство объединено через интерфейс памяти в одну адресную шину размером в 16 Мбайт с непересекающимися участками. Интерфейс памяти показан на рисунке 4. Он состоит из двух шин: шины исполняемого кода и шины данных, сигнала переключения режима доступа в чтение-запись (R/W) и сигнала подтверждения(STALL).
Сигнал подтверждения STALL делает ЦПУ совместимым с медленными последовательными и параллельными интерфейсами памяти. Когда интерфейс памяти работает медленно, ЦПУ ожидает от интерфейса подтверждения перед тем как выполнять инструкцию. В таком случае время выполнения инструкции увеличивается до значения, указанного в этом руководстве.
Шина исполняемого кода является 32-битной. Это позволяет большинству инструкций выполняться за один цикл.
Поскольку все адресное пространство объединено в общую 24-битную шину, то данные могут быть расположены в области программы (флеш-памяти), а программный код может выполняться из оперативной памяти. В последнем случае пострадает быстродействие, т.к. программный код и данные будет получаться из одной шины, которая за один такт может получить только один байт. Следовательно, время выполнения инструкции будет больше.
5 Принципы работы конвейера
Семейство микроконтроллеров STM8 имеет 3-уровневый конвейер для ускорения выполнения инструкций. Конвейер позволяет выполнять несколько операций одновременно, в отличии от их традиционного последовательного выполнения. Операции конвейера состоят из:
- Выборки
- Декодирования
- Исполнения
Программный счетчик всегда указывает на инструкцию на этапе декодирования, как показано на рисунке 5:
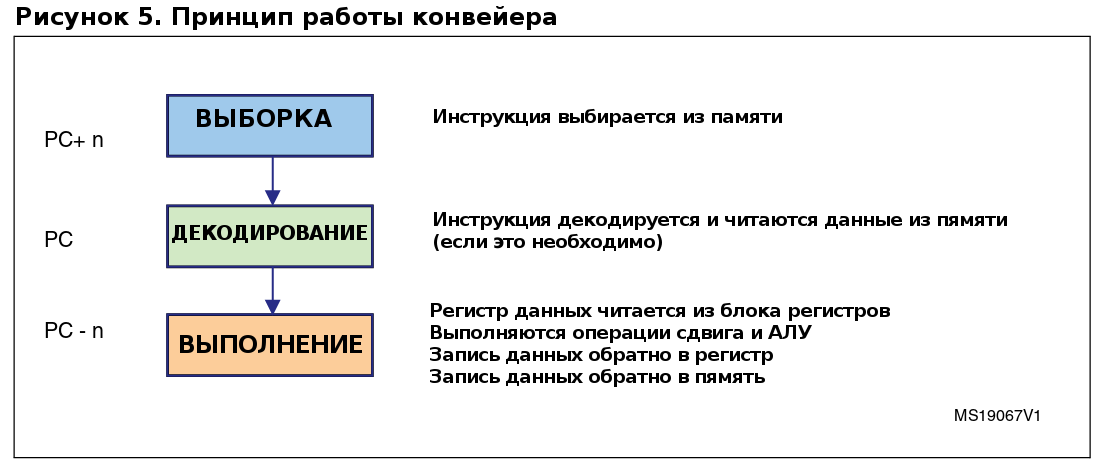
5.1 Описание уровней конвейера
Рисунок 6 и глава 5.1.1, глава 5.1.2 и глава 5.1.3 предоставляют исчерпывающую информацию о работе каждого уровня конвейера.
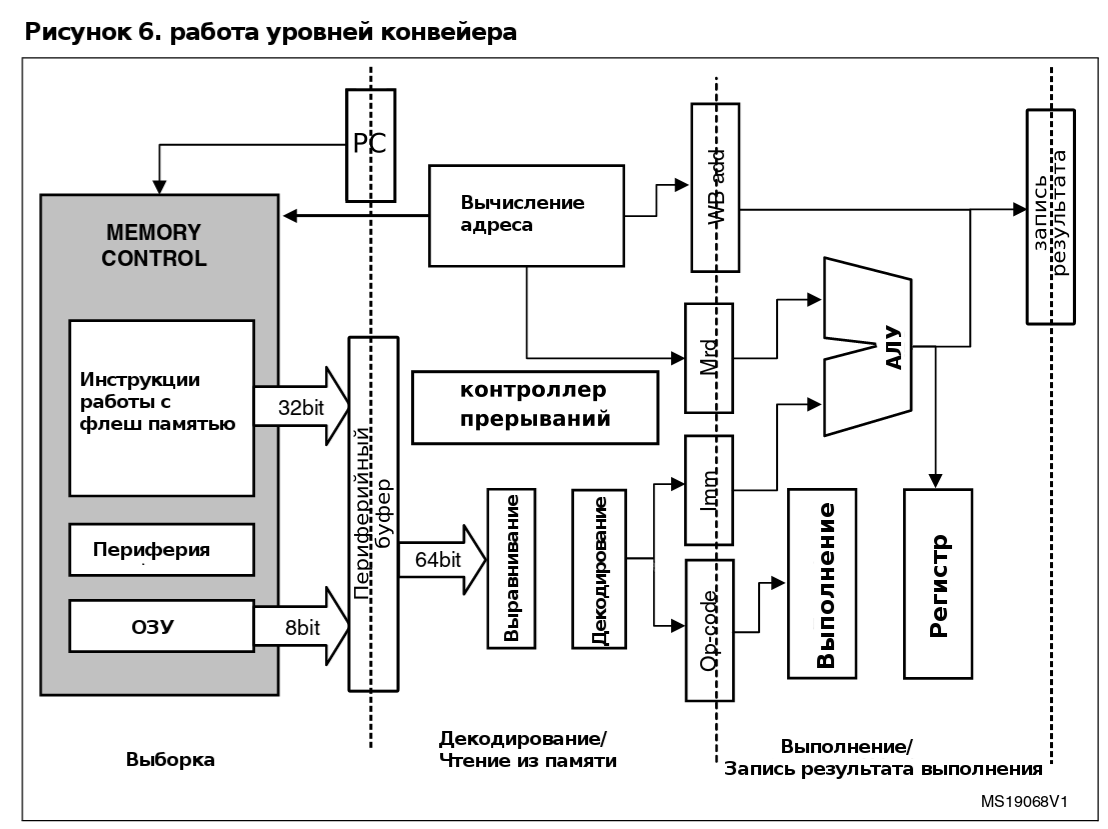
5.1.1 Этап выборки (fetch)
Первый уровень работы конвейера включает в себя 64-битный буфер выборки и 32-битный предварительный буфер. Все вместе они составляют три машинных слова, называемых F1, F2 и F3. Структура буфера позволяет загрузить любую инструкцию (более 5 байт) через F1 (и F2, если необходимо) для немедленного декодирования.
Инструкции, получаемые из флеш-памяти, имеют 32-битный размер и выравниваются по границе, кратной четырем байтам, т.е. 0хXXX0, 0xXXX4, 0xXXX8, или 0xXXXC и т.д.
В отличии от этапов декодирования и выполнения, этап выборки инструкции обращается к памяти только при необходимости. Обращение к памяти прекращается, когда буфер полностью заполнен. Это позволяет снизить энергопотребление.
Чтение инструкции из ОЗУ походит на чтение из ПЗУ. Однако, вследствие того, что шина ОЗУ является лишь 8-битной, потребуется 4 последовательных операции чтения, чтобы заполнить одно Fx слово. Вследствие этого код из ОЗУ выполняется медленнее, нежели с флеш-памяти.
5.1.2 Декодирование и вычисление адреса
Этап декодирования включает в себя операцию по выравниванию инструкции. Модуль выравнивания использует 64-битный буфер выборки, извлекает из него инструкцию и подает ее в модуль декодирования.
- Инструкция состоит из двух частей:
- опкода (1 или 2 байта);
- данных или адреса (от 0 до 3-x байт).
На этом этапе декодируется опкод. Если присутствует адресная инструкция, то сначала вычисляется непосредственный адрес, а если присутствует непосредственный операнд, то он отправляется сразу на выполнение.
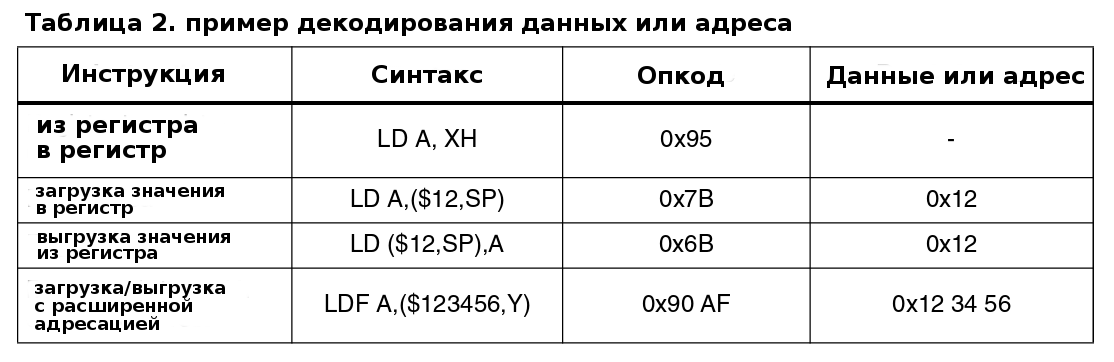
Длинные и невыровненные по границе 32 бит инструкции
Для длинных инструкций (более 5 байт) выборке необходимо дважды получать доступ к памяти, для загрузки инструкции с операндом(и). В этом случае этап декодирования приостанавливается (после декодирования опкода) в ожидании, пока выборка завершит работу.
В случае с короткими инструкциями такая ситуация может возникнуть, когда инструкция пересекает 32-битную границу.
Косвенная адресация
В случае косвенной индексации ЦПУ приостанавливает работу в ожидании пока считается указатель из памяти данных (т.е. из ОЗУ). Число пропускаемых при этом циклов зависит от длины указателя (короткий, длинный или расширенный).
5.1.3 Этап исполнения
На этапе исполнения инструкция выполняется, а результат заносится в аккумулятор, индексный регистр или в ОЗУ.
5.2 Конфликты на шине данных
Три типа операций получают доступ к памяти данных:
- вычисление адреса в случае косвенной адресации;
- операция чтения: получение исходного операнда;
- операция записи: сохранение или операция чтения-модификации-записи.
В случае одновременного доступа к одной и той же области памяти обоих уровней выполнения конвейера: для записи (при выполнении) и для чтения (при декодировании), операция декодирования приостанавливается, пока этап выполнения не освободит ресурс.
5.3 Примеры работы конвейера
Ниже приводятся несколько примеров работы конвейера. Приведенные в примерах количество циклов требуемых для этапов декодирования и выполнения, соответствуют минимальному числу для каждой инструкции. В некоторых случаях, в зависимости от последовательности инструкций, для выполнения той или иной инструкции может потребоваться большее количество циклов, нежели было указано в документации.
5.4 Предварительное соглашение
Хотя для этапов декодирования и выполнения некоторых инструкций требуется различное число циклов, ради упрощения, в этом разделе было принято соглашение обеспечивающее хорошее соответствие с реальностью:
- Будем считать, что для этапа декодирования требуется только один цикл;
- Этап декодирования занимает несколько циклов, равных:
Cy = DecCy + ExeCy - 1
где:
Cy — количество циклов используемых для выполнения инструкции. В случае декодирования и выполнения, это соответствует минимальному количеству циклов необходимых для выполнения инструкции, и не учитывает влияние от последовательности инструкций.
DecCy - точное количество циклов декодирования.
ExeCy - точное количество циклов выполнения.
Этап декодирования следующей инструкции начинается на последнем цикле этапа выполнения предыдущей инструкции. В случаях инструкций выполняющих сброс очереди конвейера, соглашение состоит в том, что выборка следующей команды начинается в последний цикл этапа выполнения предыдущей инструкции.
Точное количество циклов (см. таблицу 3) и количество циклов полученных при использовании этого соглашения (см. таблицу 4) одинаково.
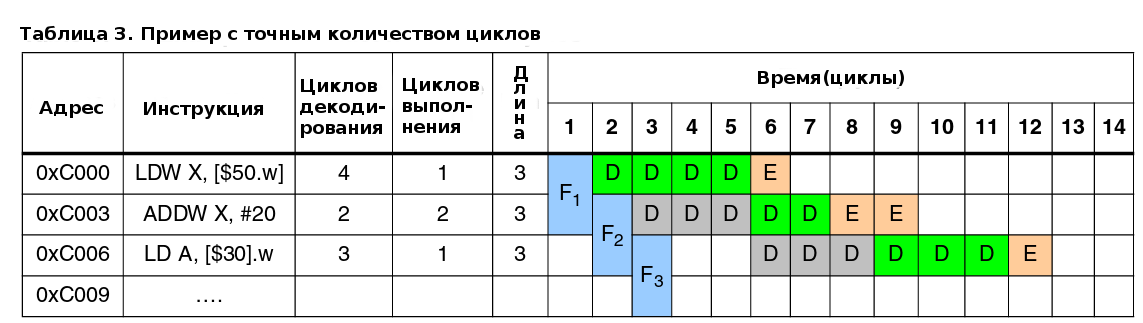
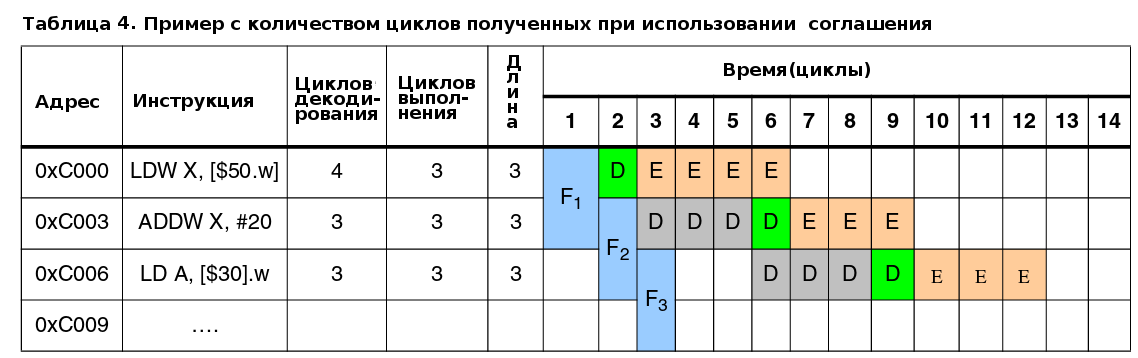

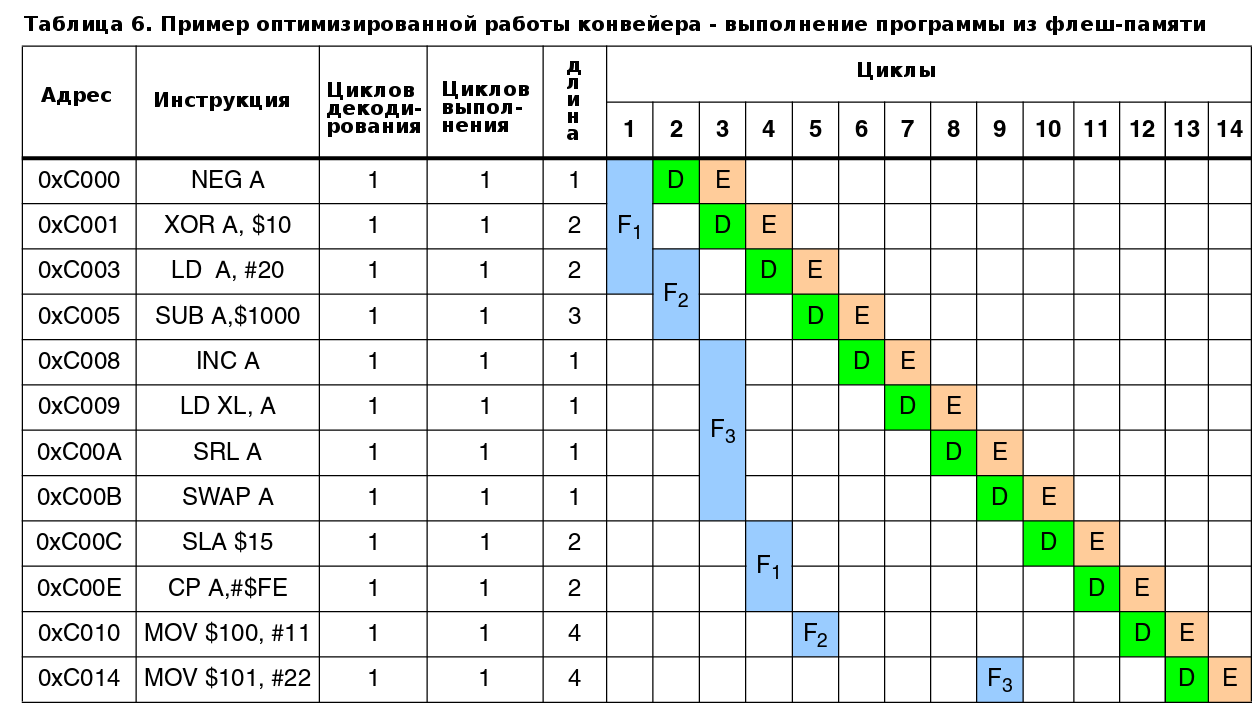
5.4.1 Пример оптимизированной работы конвейера - выполнение программы из флеш-памяти
В примере показанном в таблице 6, исполняемый код извлекается из флеш-памяти через 32-битную шину. Т.е., необходимо три цикла для заполнения всего 96-битного буфера выборки. Каждый цикл загружает одно машинное слово в регистры буфера выборки: F1, F2, F3. Следующая операция выборки для регистра Fx сможет стартовать только когда все инструкции содержащиеся в нем будут декодированы. По таблице видно, что только в 9-ом цикле последняя инструкция (SWAP A) содержащаяся в регистре F3 будет декодирована и операция выборки сможет загрузить в F3 новое значение.

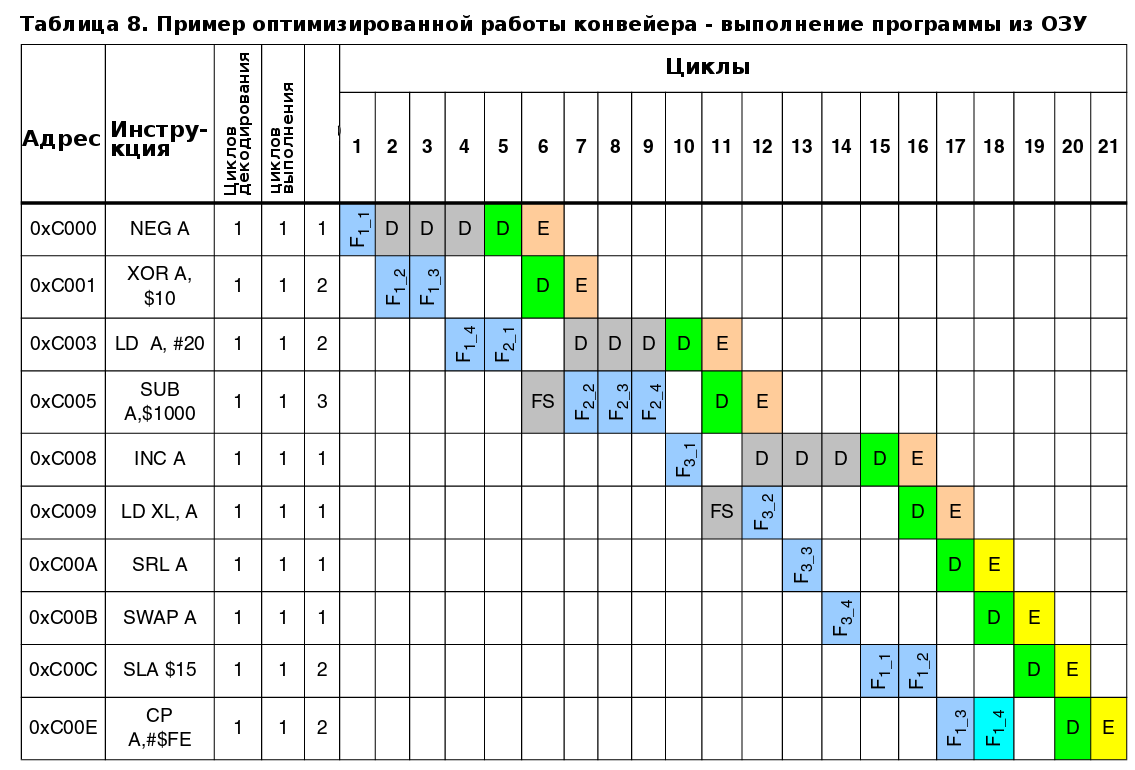
5.4.2 Пример оптимизированной работы конвейера - выполнение программы из ОЗУ
В примере показанном в таблице 8, программа считывается из ОЗУ через 8-битную шину. В этом случае требуется 12 циклов чтобы заполнить 96-битный буфер выборки. Каждые 4-е цикла, одно машинное слово загружается в регистр Fx. Декодирование первой инструкции регистра Fx начинается только тогда, кода это регистр полностью загружен. В примере это происходит на 4-м цикле, и первая инструкция (NEG A) начинает выполняться только на пятом цикле.
В случае необходимости чтения или записи в ОЗУ, этап выборки может быть приостановлен. Это происходит на 6-м цикле, когда требуется получить содержимое адреса ОЗУ 10 для декодирования инструкции XOR A,$10.
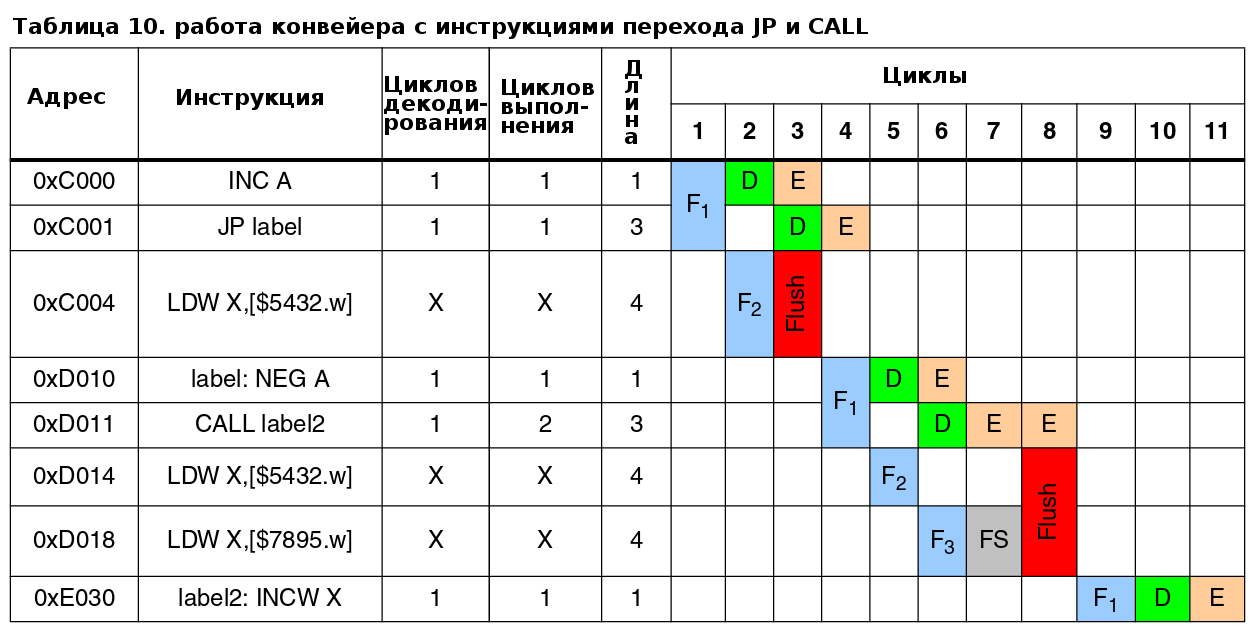
5.4.3 Пример работы конвейера с инструкциями перехода JP и CALL
В примере данном в таблице 10, выполняются переходы после инструкций JP/CALL. Тогда кеш инструкций содержащийся в буфере выборки теряется (происходит очистка буфера, т.н. "Flush"), и его требуется заполнить новыми инструкциями. Начало выборки зависит от выполняемой инструкции.
Для инструкции перехода JP, выборка начнется во время последнего цикла выполнения инструкции.
Для инструкции вызова подпрограммы CALL, она стартует только после полного выполнения инструкции.

5.4.4 Приостановка конвейера
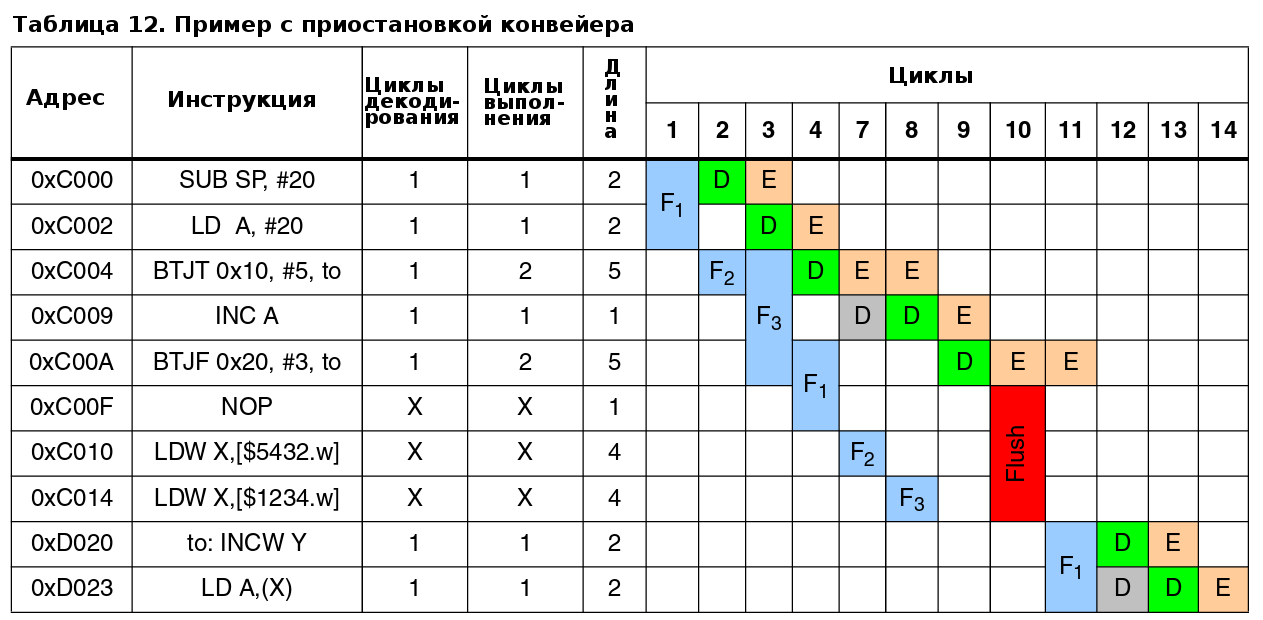
Этап декодирования может быть приостановлен, если выполнение длится более одного цикла.
Очистка очереди конвейера происходит в случае перехода. Выборка адреса перехода осуществляется во время второго цикла инструкции BTJF.
Этап декодирования также может быть приостановлен когда используемая память или регистр изменяются во время выполнения предыдущей инструкции. В примере данном в таблице 12, инструкция INCW Y записывает в X регистр в течении первого цикла выполнения. В итоге, следующая инструкция LD A,(X) не может прочитать источник в X регистре.

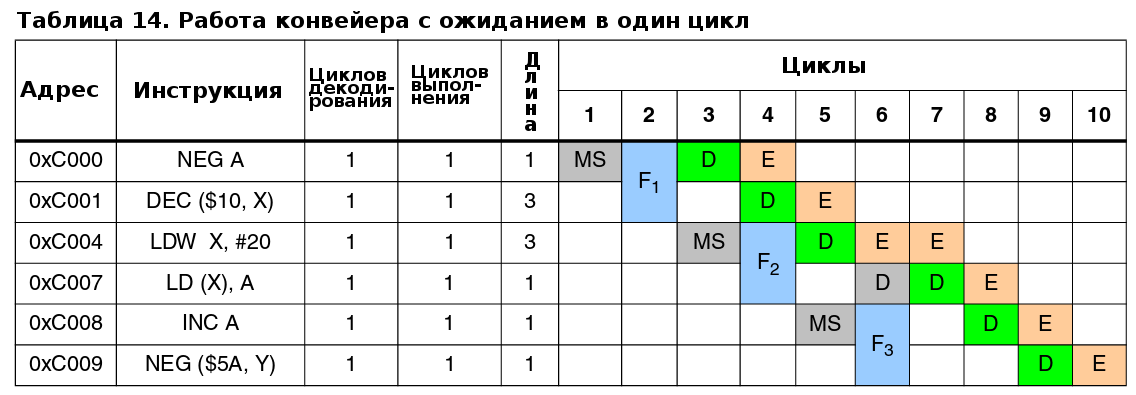
5.4.5 Работа конвейера с ожиданием в один цикл
В примере приведенном в таблице 14, выборка выполняется за 2 цикла, и выборка в регистры не перекрывается(по строке таблицы).
Если инструкция декодируется / выполняется в течение последних 2 циклов выборки, то состояние приостановки приравнивается к состоянию выполнения.